10月9日,蚂蚁集团推出并开源万亿参数的通用语言模型Ling-1T,该模型也是其迄今为止开源的参数规模最大的推理大模型。至此,继月之暗面Kimi K2、阿里Qwen3-Max之后,又一位重量级选手加入万亿参数大模型阵营。
测评数据显示,在有限输出Token条件下, Ling-1T在多项复杂推理基准测试中表现抢眼。此外,在代码生成、软件开发、竞赛数学、专业数学、逻辑推理等高难度任务中,Ling-1T的表现也优于多数同类开源模型。
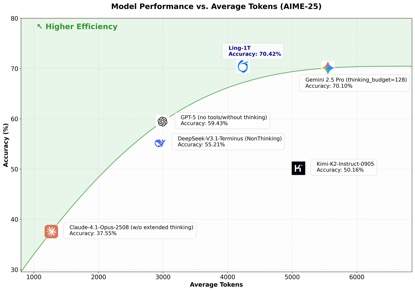
其中,在竞赛数学榜单AIME 25中,Ling-1T以约4000个Token的平均消耗,实现70.42%的准确率,高于部分同类模型在更高Token消耗下的表现。 据蚂蚁百灵团队介绍,Ling-1T沿用Ling 2.0架构,在超过20T高质量、高推理密度的语料上完成预训练,上下文窗口最高支持128K。通过“中训练+后训练”的演进式思维链方法,模型在推理能力方面有所提升。
Ling-1T全程采用 FP8 混合精度训练(部分技术已开源),是目前已知规模最大的使用FP8训练的基座模型。该训练方式可以节省显存、优化并行策略及提升训练速度。 在强化学习阶段,蚂蚁百灵团队提出了LPO方法,以“句子”为粒度进行策略优化,为万亿参数模型的稳定训练提供支持。该方法有助于在语义层面更准确地对齐奖励信号与模型行为。
此外,蚂蚁百灵团队提出了“语法-功能-美学”的混合奖励机制,在确保代码正确、功能完善的同时增强模型对视觉表达的理解。在ArtifactsBench 前端能力基准上,Ling-1T得分59.31,在可视化和前端开发任务领域,仅次于Gemini-2.5-Pro-lowthink的得分60.28。
除Ling-1T模型外,蚂蚁百灵团队还在训练万亿参数级的深度思考大模型Ring-1T,已在9月30日开源了preview版。目前,开发者通过Hugging Face和蚂蚁百宝箱等平台均可体验Ling-1T模型。
(《财经》新媒体综编)

